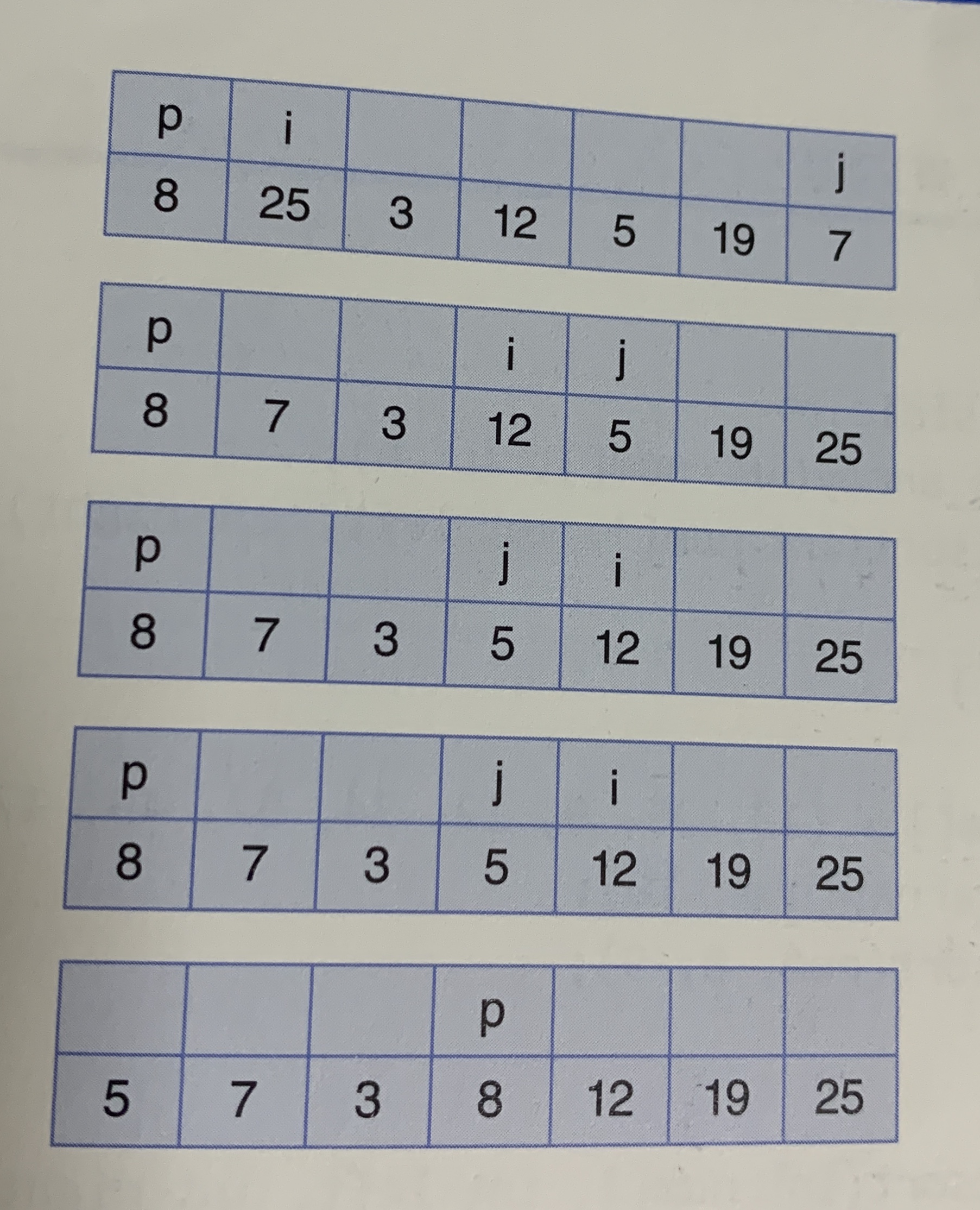
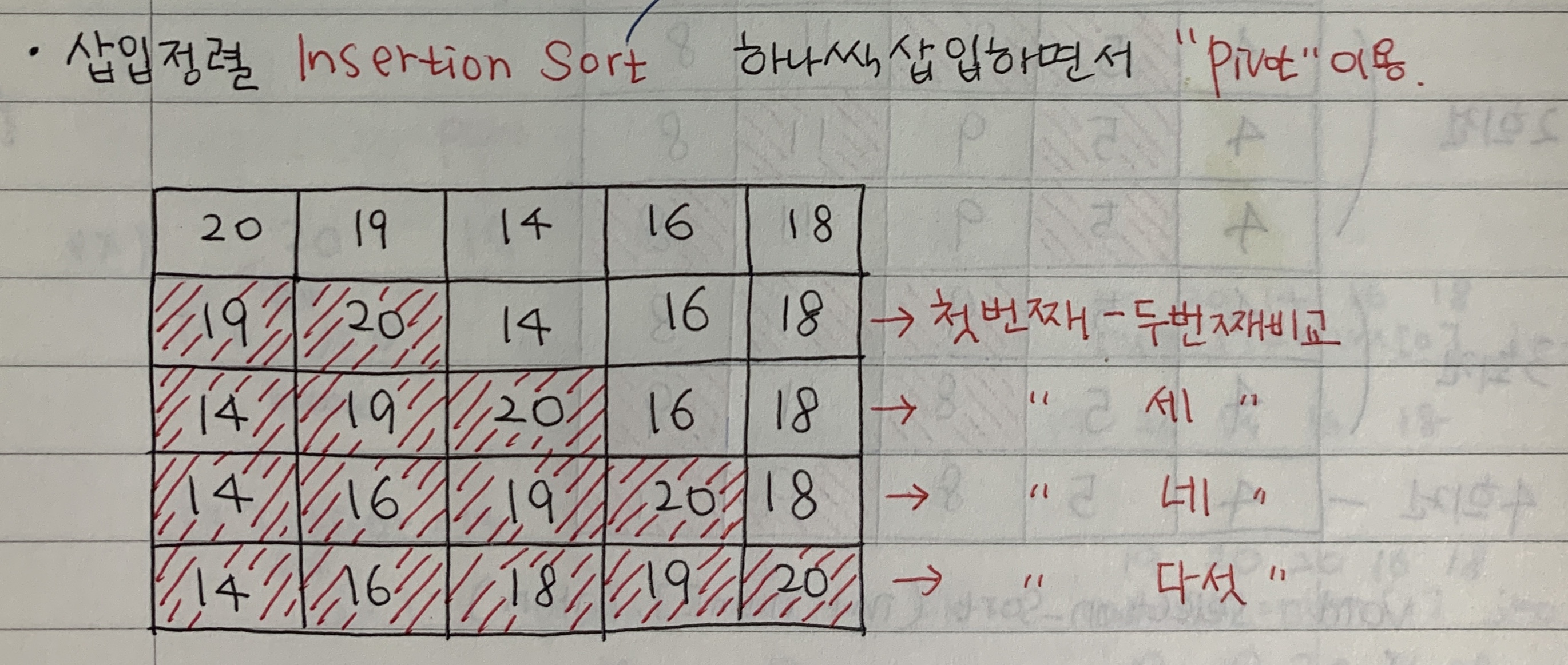
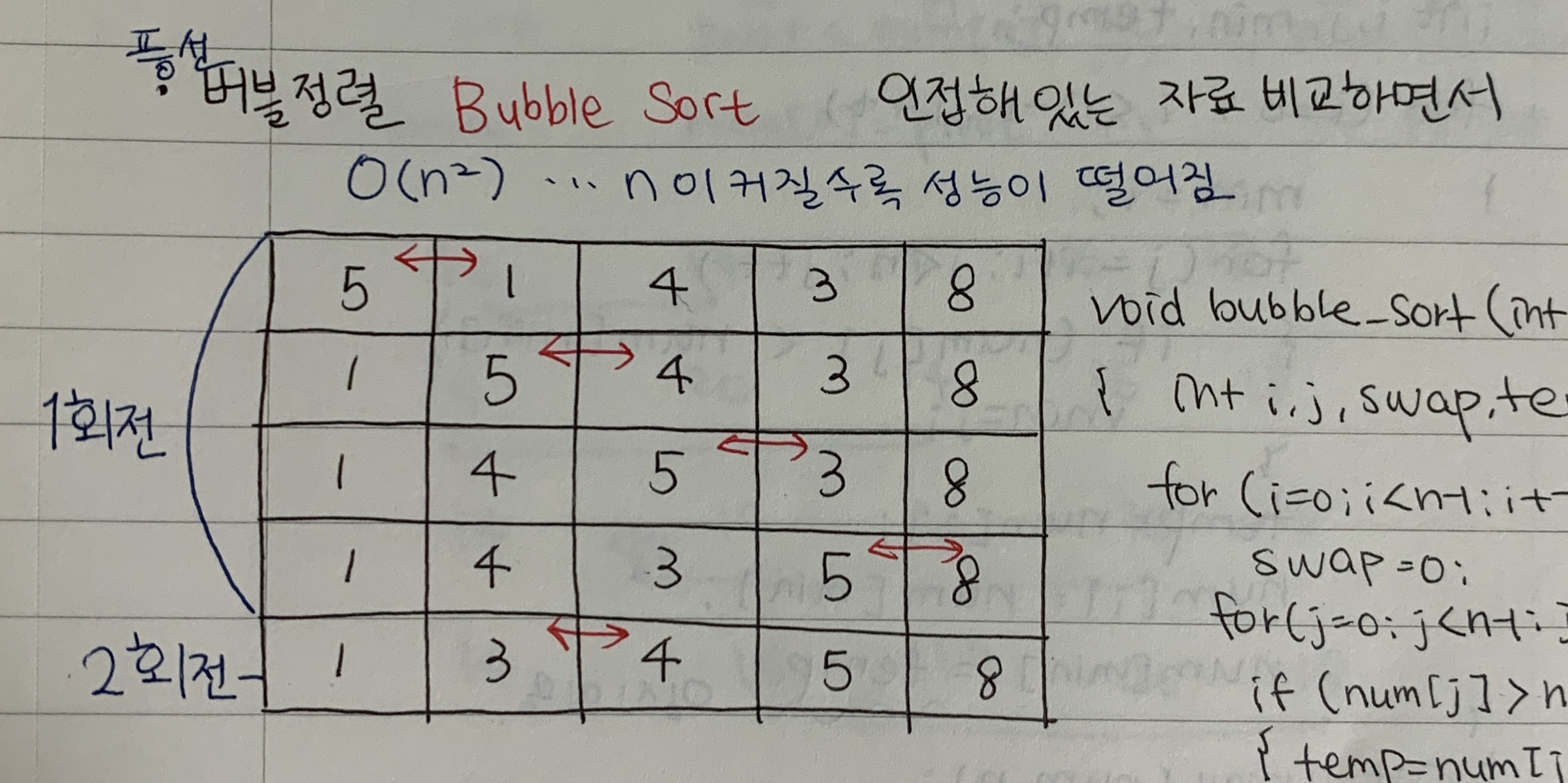
📌트리(Tree) root 와 서브 트리로 구성된 계층형 hierarchical 자료 구조 📌이진 트리 (Binary Tree) 각 노드는 최대 2개의 자식노드 [ 용어 정리 ] ✔️단말 노드 자식 노드가 없는 차수가 0인 노드 ✔️레벨 루트는 레벨 1이며 단말 노드 방향으로 1씩 증가 ✔️부모-자식 부모와 자식 노트의 레벨 차이 1 ✔️형제 형제 노트는(sibling) 부모가 동일한 자식 노드들 ✔️조상 노드 (Ancestor node) 특정 노드에서 루트까지 경로에 존재하는 모든 노드 ✔️자손 노드 (Descendant node) 특적 노드의 서브 트리에 존재하는 모든 노드 ✔️내부 노드(Internal node) 자식이 최소한 1개 이상인 노드 ✔️외부 노드(External node) 자식이 없는 ..