👉 간단히 말하는 머신러닝의 프로세스
1. 첫단추는 "비즈니스 이해"
비즈니스 이해하고 목표를 설정하게 되면 Data를 targeting하게 된다
2. Data 전처리
3. Data 탐색
4. 머신러닝 -> 학습 -> 결과 (결과가 안 좋으면 다시 한번 머신러닝 돌리기)
📌Machine Learning Pipeline
| Process | Description | Output |
| Business Understand (비즈니스 이해) |
비즈니스 이해 후 목표 설정 | |
| 1) Data Loading | DataSet 불러오기 (csv, excel, sql...) - train set (학습용, 레이블 O) - test set (평가용, 레이블 X) |
DataSets (All, Train, Test) |
| 2) Data Preprocessing (전처리) |
결측치 처리, 이상치 처리, 데이터 보정 | 데이터 정리 |
| 3) Feature Engineering 4) Feature Selection/Extraction (데이터 탐색) |
Feature Engineering - 기존 데이터 활용하여 신규 데이터 열 생성 - 카테고리 데이터 변형 (ex. 계정, 년도/월/일 등) Feature Selection/Extraction - 중요 데이터 선정 - 필요 없는 데이터 삭제 (relation 적은 data) |
데이터 정리 |
| 5) Data Splitting | Train Datasets을 학습과 학습 평가용으로 분할 - 학습 평가용 (20%), 학습용 (80%)로 분할 |
x_train, y_train x_valid, y_valid |
| 6) Modeling | 학습할 모델 생성 - 회귀 : 연속형 레이블 (LR, Ridge, Lasso RF, GB) - 분류 : 범주형 레이블 (LR, DT, RF, GB) |
MODEL |
| 7) Training | 학습데이터 이용하여 생성된 모델 학습 - 학습데이터를 넣어 예측값 출력 > pred_train - 학습 평가 데이터 넣어 예측값 출력 > pred_test |
pred_train pred_valid |
| 8) Evaluation (-> Hyper Parameter Tuning -> 다시 Modeling) |
예측값과 실제값을 비교하여 성능 평가 if) 학습 데이터와 학습 평가 데이터의 차이가 크다면 문제 |
train score test score |
| 9) Inferencing | 학습된 모델에 예측하고자 하는 데이터 넣어 예측 -Test Set or 미래에 발생할 데이터 |
pred_test |
| 10) Submission | 예측 결과 제출 | RANK |
1) 데이터 가져오기
✔️ CSV, Excel, SQL의 경우 Pandas 함수 이용
-read_csv / read_excel / read_sql
✔️ scikig-learn의 Datasets 함수 이용
2) 데이터 전처리
✔️ 결측치 처리 : fillna, dropna
✔️ 이상치 처리 : IQR, Sigma Rule
✔️ 데이터 보정
✔️ Data Encoding
One Hot (A, B, C) > (1,0,0)(0,1,0)(0,0,1)
Label (A, B, C) > (1,2,3)
3) Feature Engineering
✔️ Model 학습에 도움이 되는 방향으로 전처리
ex. 날짜 데이터 활용하여 Model이 학습에 유용한 데이터로 바꿔줌 (요일/주차)
4) Feature Selection/Extraction
✔️ 모두 값이 같다? -> 의미 없는 특성이므로 제거
✔️ y값과 상관관계가 낮은 특성? -> 제거
✔️ Model에 영향이 낮은 특성? -> Feature Importance 활용하여 제거
5) Data Splitting
✔️ 학습을 위한 데이터를 분리, (x1, x2, x3, x4) 와 (y) 따로
6) Modeling
[ 레이블에 따른 모델 선정 ]
✔️ 범주형 레이블 (분류, Classification) : 레이블별 데이터의 차이를 찾아서 분류
ex. Logistic Regression, Decision Tree, Random Forest, Gradient Boosting...
✔️ 연속형 레이블 (회귀, Regression) : 예측된 모형 이용하여 향후 나올 값 예측
ex. Linear Regression, Ridge, Lasso, Random Forest, Gradient Boosting...
7) Training
✔️ 학습 데이터 세트를 이용하여 모델 학습
8) Evaluation
✔️ 학습 및 학습 평가 데이터 세트를 이용하여 모델 평가
9) Inferencing 10) Submission
✔️ 예측 데이터 추론과 결과 제출
미래의 데이터 또는 제출용 데이터를 Model에 입력하여 평가 (학습 데이터와 동일한 특성의 순서 및 개수 사용)
📌Machine Learning
. 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 algorithm과 tech를 개발하는 분야
. 컴퓨팅 성능의 향상과 빅데이터로 인해 비즈니스 가치를 창출할 수 있음
❓ 이런 문제 유형에 이용한다
- algorithm의 부재로 명시적 문제 해결이 불가능할 때
- 프로그래밍이 어려울 때 (음석 인식)
- 지속적으로 변화할 때 (자율 주행)
❓ 기존 Programming VS Machine Learning
기존 프로그래밍은..
-> 사람이 직접 프로그램을 만들고 컴퓨터에 처리 방법을 넘겨주고 지시하면 컴퓨터가 처리 후 처리 결과를 전달
머신 러닝은..
-> 컴퓨터에게 처리 방법을 주는 것이 아니라 원하는 결과를 줌으로써 컴퓨터가 처리 방법을 생성하고 처리 결과를 건네줌
📌학습방법
a) 지도 학습(Supervised Learning) -> 타겟하는 Y데이터가 있다
- 데이터를 이용하여 주어진 데이터 해석할 수 있는 모델 만들고, 이를 바탕으로 새로운 데이터 추정
- 좋은 학습 결과 얻기 위해 양질의 많은 데이터 확보 필요
- Classification, Predict 문제에서 이용
b) 비지도 학습(Unsupervised Learning) -> Y데이터가 있다
- 주어진 데이터에 대한 결과가 없는 데이터를 이용해 주어진 데이터에 내재된 패턴, 특성, 구조를 찾아서 학습
- 지도학습과 다른 점 -> 학습 데이터 넣어주면 '스스로' 학습.. 편리하지만 지도 학습에 비해 결과는 좋지 않음
- Clustering 문제에서 이용
c) 준지도 학습(Semi Supervised Learning)
- 레이블이 표시된 데이터와 표시되지 않은 데이터를 모두 훈련에 사용 (지도 학습과 반지도 학습 중간)
- 대개의 경우 준지도 학습에 사용되는 훈련 데이터는 레이블이 표시된 데이터가 적고 표시되지 않은 데이터를 많이 갖고 있는 상황에서 주로 이용 (이상 감지)
d) 강화 학습(Reinforcement Learning)
- stage를 진행하는 중간중간에 가상의 에이전트가 stage를 판단해 나가는 학습
- 에이전트가 특정 환경에서 현재의 상태를 인식하여 보상이 최대화되는 행동을 수행하도록 학습하는 방법
📌Machine Learning 유형 분류
| Method | Type | ML Model |
| 라벨이 있는 지도학습 Supervised Learning |
예측 Prediction | Linear Regression Regression Tree Ridge Lasso Ensemble Model ... |
| 분류 Classification | K-Nearest Neighbor Logistic Regression Random Forest Decision Tree ... |
|
| 라벨이 없는 비지도 학습 UnSupervised Learning |
군집 Clustering | K-Means Clustering DBSCAN Hierarchical Custering ... |
| 차원 축소 Dimension, Reduction | Principal Component Analysis (PCA) t-Stochastic Neighbor Embedding ... |
📌과소적합 & 과대적합
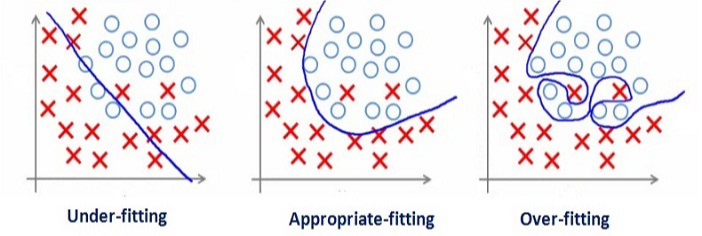
✔️ 과소적합 (Under Fitting)
정보를 충분히 학습하지 못해 설명력이 떨어지는 상태
발생한 경우 'High Bias 하다' 표현
✔️ 과대적합 (Over-Fitting)
정보 과도하게 학습하여 일반화된 설명력이 떨어지는 상태
발생한 경우 'High Variance 하다' 표현
👉 ML 기법 또는 Parameter Tuning 같은 작업을 통해 문제 해결 필요
'CDS' 카테고리의 다른 글
| Machine Learning [K-NN] (0) | 2021.11.15 |
|---|---|
| Machine Learning [Scikit-Learn] (0) | 2021.11.15 |
| Data Visulization : Seaborn(데이터 시각화) (0) | 2021.11.12 |
| Data Visulization : Matplotlib(데이터 시각화) (0) | 2021.11.12 |
| EDA (Exploratory Data Analysis) (0) | 2021.11.12 |