📌 Scaling
- 특정 알고리즘은 데이터의 관측 범위에 많은 영향이 있어 스케일링 통해 관측범위 일정하게 맞추는 작업 필요
- 주로 Standardization(표준화), Normalization(정규화) 이용
- ML모델은 data set 전체 변환하지 않고 학습 데이터만 변환 학습
👉 이전에 설명했던 iris_bunch data를 이용하여 관측을 해보자
#pandas를 이용하여 DataFrame을 만들어 iris_df에 저장
import pandas as pd
iris_df = pd.DataFrame(iris_bunch.data)
#matplotlib를 이용하여 그래프 그리기 boxplot
import matplotlib.pyplot as plt
plt.boxplot(iris_bunch.data)
plt.show()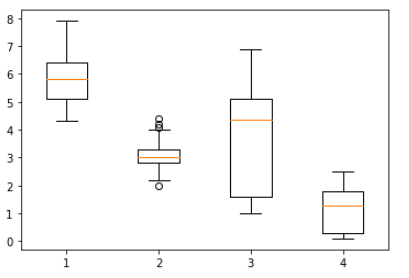
...위와 같은 boxplot 그래프가 도출된다
❗ 제대로 나왔는지 확인하기 위해서 아래 코드를 이용, iris_df Dataframe이 어떻게 생겼는가 살펴보자
iris_df.describe()
👉 보면 boxplot 하나하나가 iris_df의 column 하나하나라고 보면 된다 0,1,2,3 총 4개의 boxplot이 나오며
✔️ boxplot의 중간 주황색 선은 mean(평균값)
✔️ 위 아래 일자선은 IQR을 활용한 Max와 Min
✔️ 1 box 위아래 동그라미는 outlier
📌 정규화
- 서로 다른 특징 값을 같은 범위로 통일 시키기 위한 방법
- 최소/최대 정규화 이용하며 0~1 데이터를 변환
- sklearn.preprocessing.MinMaxScaler 이용
X(new_i) = [X(i) - min(X(i))] / [max(X(i)) - min(X(i))]
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_train_sc = scaler.fit_transform(x_train)
x_test_sc = scaler.transform(x_test)from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors = 3).fit(x_train_sc, y_train)
model.score(x_train_sc, y_train), model.score(x_test_sc, y_test)#output
(0.9714285714285714, 0.9777777777777777)
📌 표준화
- 서로 다른 분포를 비교하기 위해 표준에 맞게 통일 시키는 방법
- 평균을 0, 표준편차를 1로 변환
- sklearn.preprocessing.StandardScaler 이용
X(new_i) = [X(i) - M]/6 (이때 M은 X의 평균(mean)이며 6은 X의 표준 편차(std)
from sklearn.preprocessing import StandardScaler
scaler = MinMaxScaler()
x_train_sc = scaler.fit_transform(x_train)
x_test_sc = scaler.transform(x_test)from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors = 3).fit(x_train_sc, y_train)
model.score(x_train_sc, y_train), model.score(x_test_sc, y_test)#output
(0.9714285714285714, 0.9777777777777777)
📌 이상치(Outlier)처리
- 이상치는 중심에서 많이 떨어져 있는 값
- 평균에는 크게 영향을 끼치지만 중앙값에는 작은 영향을 미침
- 이상치 처리
✔️ 1) 표준 점수 (Standard Score, Z)로 변환 후 +- 3감마 제거
✔️ 2) IQR을 이용한 제거
✔️ 3) 도메인 지식 기반 제거와 같은 방식 주로 사용
- 표준 점수 이용할 경우 평균이 0, 표준 편차가 1인 분포로 변환한 후 +3 이상이거나 -3 이하인 경우 이상치로 판단
- IQR 이용할 경우 사분위 값 처리하여 IQR(75%-25%) 계산한 후 1.5 곱하여 처리
import matplotlib.pyplot as plt
plt.boxplot(iris_bunch.data)
plt.show()
#Boxplot을 그려서 outlier(동그라미)표식 유무로 확인#IQR 계산
Q1 = x_train['sepal width (cm)'].quantile(0.25)
Q3 = x_train['sepal width (cm)'].quantile(0.75)
IQR = Q3 - Q1
MIN = Q1 - 1.5 * IQR
MAX = Q3 + 1.5 * IQR
MIN, MAX#이상치 Outlier 조회
target = x_train[x_train['sepal width (cm)'] < MIN) |
(x_train['sepal width (cm)'] > MAX)]
target
#이상치 Outlier 제거
x_train = x_train.drop(target.index)
y_train = y_train.drop(target.index)'CDS' 카테고리의 다른 글
| Machine Learning [Coding Sample] (0) | 2021.11.16 |
|---|---|
| Machine Learning [Linear Regression] (0) | 2021.11.16 |
| Machine Learning [K-NN] (0) | 2021.11.15 |
| Machine Learning [Scikit-Learn] (0) | 2021.11.15 |
| Machine Learning Overview (0) | 2021.11.15 |