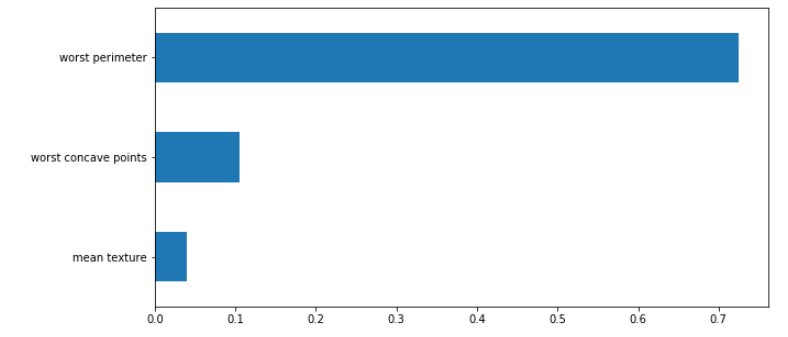
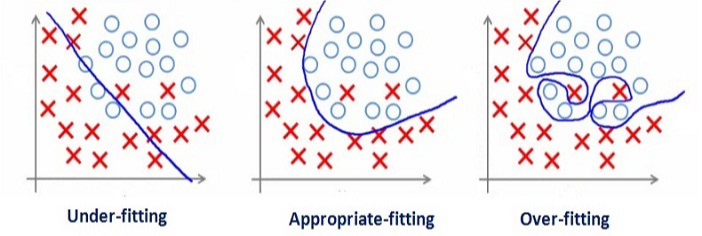
📌 Decision Tree - 트리 구조를 이용하여 데이터 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내는 알고리즘 - 분류 (범주형 레이블)와 회귀 (연속형 레이블)에 모두 사용 가능 - 각 변수 영역을 재귀적으로 분할하면서 규칙 생성 (If-else) - 분류의 경우 특성의 영역을 분할하면서 정보 균일도가 높게 하도록 분할하며 회귀의 경우 잔차 제곱합이 최소가 되도록 분할 ✔️ 스무고개와 유사 Ex. 어머니가 소고기를 사실까? 1. 어머니가 오른쪽 시장으로 가면 정육점이 멀어지므로 소고기를 살 확률이 낮아진다. 2. 어머니가 왼쪽 시장으로 가면 정육점이 가까워지므로 소고기를 살 확률이 높아진다. 여기서 확률이 높은 2번을 택하고 1. 정육점 사장님이 오늘 할인을 해주시면 소고기를 살 ..